Publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
- ICLR
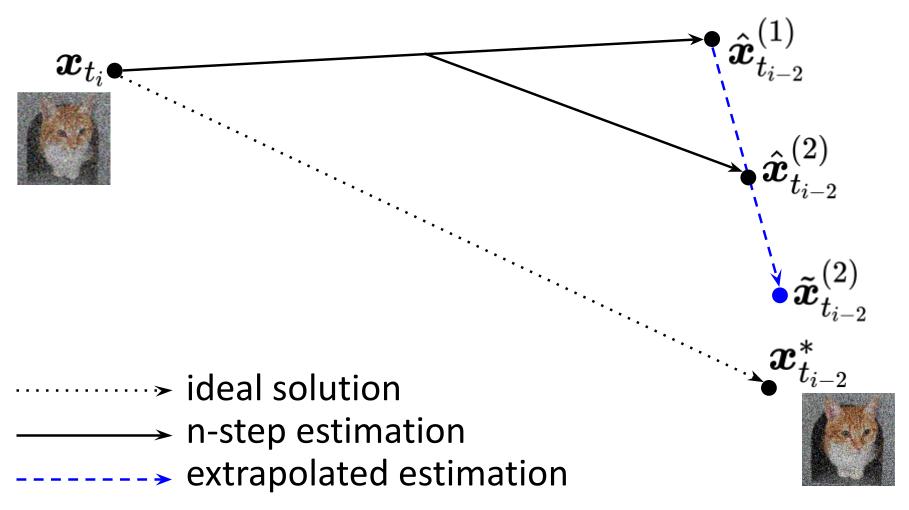 Enhanced Diffusion Sampling via Extrapolation with Multiple ODE SolutionsJinyoung Choi, Junoh Kang, and Bohyung HanIn ICLR, 2025
Enhanced Diffusion Sampling via Extrapolation with Multiple ODE SolutionsJinyoung Choi, Junoh Kang, and Bohyung HanIn ICLR, 2025Diffusion probabilistic models (DPMs), while effective in generating high-quality samples, often suffer from high computational costs due to their iterative sampling process. To address this, we propose an enhanced ODE-based sampling method for DPMs inspired by Richardson extrapolation, which reduces numerical error and improves convergence rates. Our method, RX-DPM, leverages multiple ODE solutions at intermediate time steps to extrapolate the denoised prediction in DPMs. This significantly enhances the accuracy of estimations for the final sample while maintaining the number of function evaluations (NFEs). Unlike standard Richardson extrapolation, which assumes uniform discretization of the time grid, we develop a more general formulation tailored to arbitrary time step scheduling, guided by local truncation error derived from a baseline sampling method. The simplicity of our approach facilitates accurate estimation of numerical solutions without significant computational overhead, and allows for seamless and convenient integration into various DPMs and solvers. Additionally, RX-DPM provides explicit error estimates, effectively demonstrating the faster convergence as the leading error term’s order increases. Through a series of experiments, we show that the proposed method improves the quality of generated samples without requiring additional sampling iterations.
2024
- NeurIPS
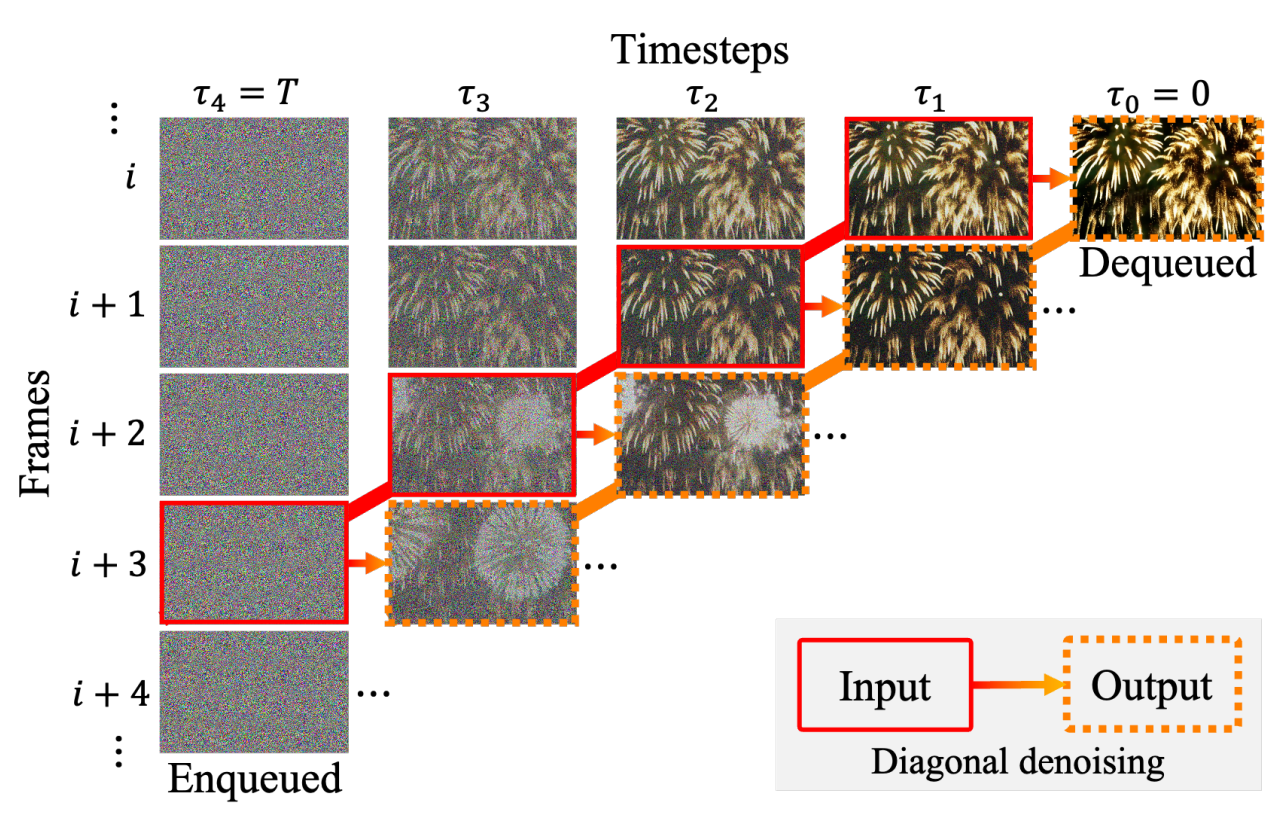 FIFO-Diffusion: Generating Infinite Videos from Text without TrainingJihwan Kim*, Junoh Kang*, Jinyoung Choi, and Bohyung HanIn NeurIPS, 2024
FIFO-Diffusion: Generating Infinite Videos from Text without TrainingJihwan Kim*, Junoh Kang*, Jinyoung Choi, and Bohyung HanIn NeurIPS, 2024We propose a novel inference technique based on a pretrained diffusion model for text-conditional video generation. Our approach, called FIFO-Diffusion, is conceptually capable of generating infinitely long videos without training. This is achieved by iteratively performing diagonal denoising, which concurrently processes a series of consecutive frames with increasing noise levels in a queue; our method dequeues a fully denoised frame at the head while enqueuing a new random noise frame at the tail. However, diagonal denoising is a double-edged sword as the frames near the tail can take advantage of cleaner ones by forward reference but such a strategy induces the discrepancy between training and inference. Hence, we introduce latent partitioning to reduce the training-inference gap and lookahead denoising to leverage the benefit of forward referencing. We have demonstrated the promising results and effectiveness of the proposed methods on existing textto-video generation baselines. Generated video samples and source codes are available at our project page.
- arXiv
 A Training-Free Defense Framework for Robust Learned Image CompressionMyungseo Song, Jinyoung Choi, and Bohyung HanarXiv preprint, 2024
A Training-Free Defense Framework for Robust Learned Image CompressionMyungseo Song, Jinyoung Choi, and Bohyung HanarXiv preprint, 2024We study the robustness of learned image compression models against adversarial attacks and present a training-free defense technique based on simple image transform functions. Recent learned image compression models are vulnerable to adversarial attacks that result in poor compression rate, low reconstruction quality, or weird artifacts. To address the limitations, we propose a simple but effective two-way compression algorithm with random input transforms, which is conveniently applicable to existing image compression models. Unlike the naïve approaches, our approach preserves the original rate-distortion performance of the models on clean images. Moreover, the proposed algorithm requires no additional training or modification of existing models, making it more practical. We demonstrate the effectiveness of the proposed techniques through extensive experiments under multiple compression models, evaluation metrics, and attack scenarios.
- CVPR
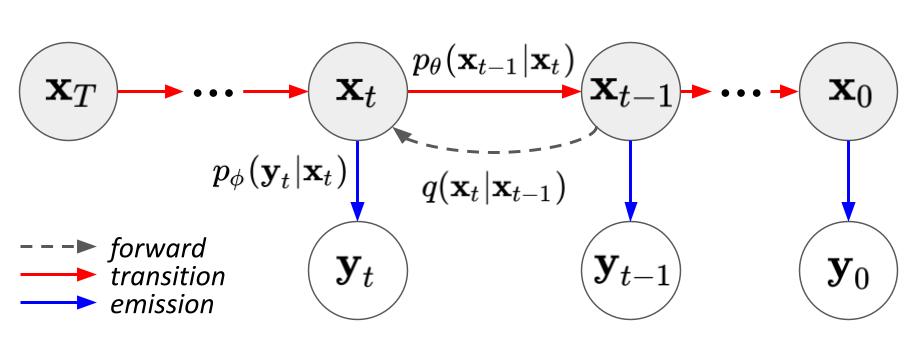 Observation-Guided Diffusion Probabilistic ModelsJunoh Kang*, Jinyoung Choi*, Sungik Choi, and Bohyung HanIn CVPR, 2024
Observation-Guided Diffusion Probabilistic ModelsJunoh Kang*, Jinyoung Choi*, Sungik Choi, and Bohyung HanIn CVPR, 2024We propose a novel diffusion-based image generation method called the observation-guided diffusion probabilistic model (OGDM), which effectively addresses the tradeoff between quality control and fast sampling. Our approach reestablishes the training objective by integrating the guidance of the observation process with the Markov chain in a principled way. This is achieved by introducing an additional loss term derived from the observation based on a conditional discriminator on noise level, which employs a Bernoulli distribution indicating whether its input lies on the (noisy) real manifold or not. This strategy allows us to optimize the more accurate negative log-likelihood induced in the inference stage especially when the number of function evaluations is limited. The proposed training scheme is also advantageous even when incorporated only into the fine-tuning process, and it is compatible with various fast inference strategies since our method yields better denoising networks using the exactly the same inference procedure without incurring extra computational cost. We demonstrate the effectiveness of our training algorithm using diverse inference techniques on strong diffusion model baselines. Our implementation is available at https://github.com/Junoh-Kang/OGDM_edm.
2022
- NeurIPS
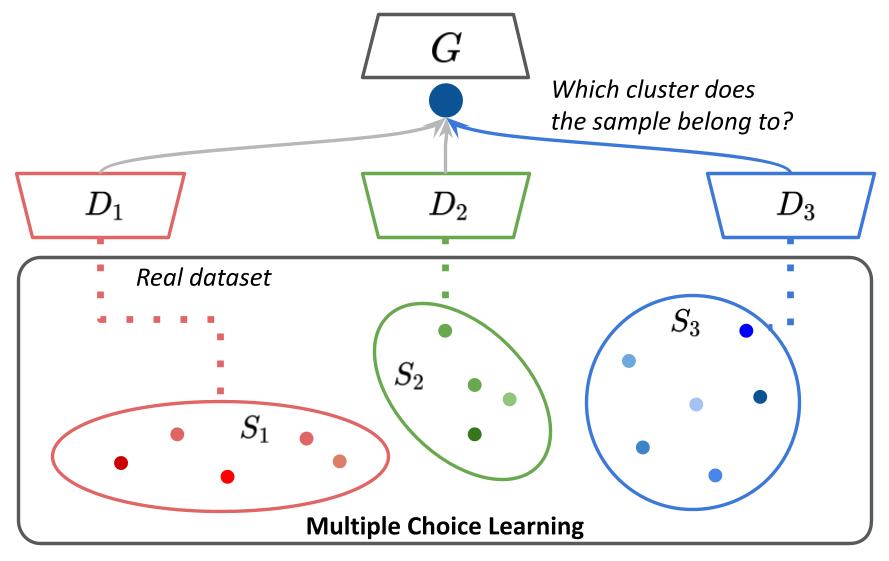 MCL-GAN: Generative Adversarial Networks with Multiple Specialized DiscriminatorsJinyoung Choi, and Bohyung HanIn NeurIPS, 2022
MCL-GAN: Generative Adversarial Networks with Multiple Specialized DiscriminatorsJinyoung Choi, and Bohyung HanIn NeurIPS, 2022We propose a framework of generative adversarial networks with multiple discriminators, which collaborate to represent a real dataset more effectively. Our approach facilitates learning a generator consistent with the underlying data distribution based on real images and thus mitigates the chronic mode collapse problem. From the inspiration of multiple choice learning, we guide each discriminator to have expertise in a subset of the entire data and allow the generator to find reasonable correspondences between the latent and real data spaces automatically without extra supervision for training examples. Despite the use of multiple discriminators, the backbone networks are shared across the discriminators and the increase in training cost is marginal. We demonstrate the effectiveness of our algorithm using multiple evaluation metrics in the standard datasets for diverse tasks.
2021
- ICCV
 Variable-Rate Deep Image Compression through Spatially-Adaptive Feature TransformMyungseo Song, Jinyoung Choi, and Bohyung HanIn ICCV, 2021
Variable-Rate Deep Image Compression through Spatially-Adaptive Feature TransformMyungseo Song, Jinyoung Choi, and Bohyung HanIn ICCV, 2021We propose a versatile deep image compression network based on Spatial Feature Transform (SFT), which takes a source image and a corresponding quality map as inputs and produce a compressed image with variable rates. Our model covers a wide range of compression rates using a single model, which is controlled by arbitrary pixel-wise quality maps. In addition, the proposed framework allows us to perform task-aware image compressions for various tasks, e.g., classification, by efficiently estimating optimized quality maps specific to target tasks for our encoding network. This is even possible with a pretrained network without learning separate models for individual tasks. Our algorithm achieves outstanding rate-distortion trade-off compared to the approaches based on multiple models that are optimized separately for several different target rates. At the same level of compression, the proposed approach successfully improves performance on image classification and text region quality preservation via task-aware quality map estimation without additional model training. The code is available at the project website: https://github.com/micmic123/QmapCompression.
2020
- ECCV
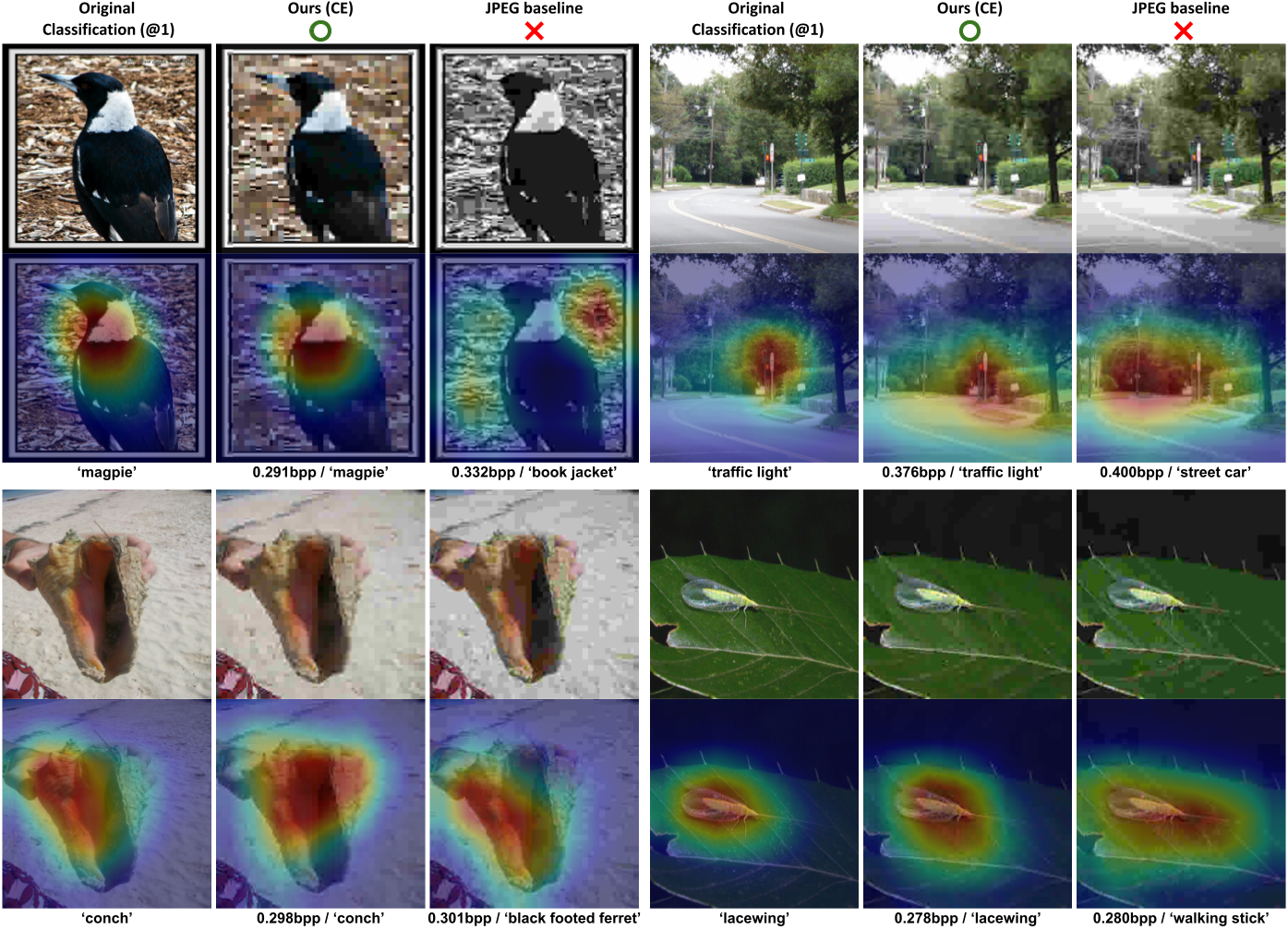 Task-Aware Quantization Network for JPEG Image CompressionJinyoung Choi, and Bohyung HanIn ECCV, 2020
Task-Aware Quantization Network for JPEG Image CompressionJinyoung Choi, and Bohyung HanIn ECCV, 2020We propose to learn a deep neural network for JPEG image compression, which predicts image-specific optimized quantization tables fully compatible with the standard JPEG encoder and decoder. Moreover, our approach provides the capability to learn task-specific quantization tables in a principled way by adjusting the objective function of the network. The main challenge to realize this idea is that there exist non-differentiable components in the encoder such as run-length encoding and Huffman coding and it is not straightforward to predict the probability distribution of the quantized image representations. We address these issues by learning a differentiable loss function that approximates bitrates using simple network blocks—two MLPs and an LSTM. We evaluate the proposed algorithm using multiple task-specific losses—two for semantic image understanding and another two for conventional image compression—and demonstrate the effectiveness of our approach to the individual tasks.